
We recently set up a Spark SQL (Spark) and decided to run some tests to compare the performance of Spark and Amazon Redshift. For our benchmarking, we ran four different queries: one filtration based, one aggregation based, one select-join, and one select-join with multiple subqueries. We ran these queries on both Spark and Redshift on datasets ranging from six million rows to 450 million rows.

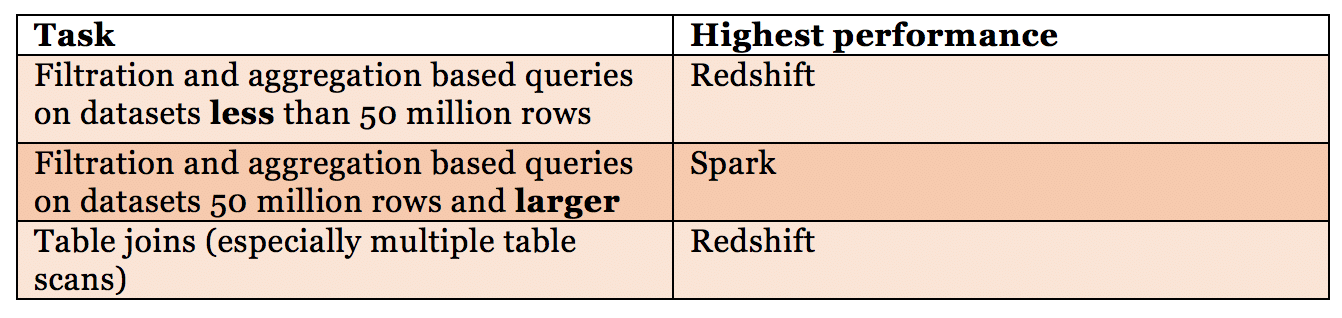
These tests led to some interesting discoveries. First, when performing filtration and aggregation based queries on datasets larger than 50 million rows, our Spark cluster began to out-perform our Redshift database. As the size of the data increased, so did the performance difference. However, when performing the table joins – and in particular the multiple table scans involved in our subqueries – Redshift outperformed Spark (even on a table with hundreds of millions of rows!).
The Details
Our largest Spark cluster utilized an m1.Large master node, and six m3.xLarge worker nodes. Our aggregation test ran between 2x and 3x faster on datasets larger than 50 million rows. Our filtration test had a similar level of gains, arriving at a similar level of data size.
However, our table scan testing showed the opposite effect at all levels of data size. Redshift generally ran slightly faster than our Spark cluster, the difference in performance increasing as the volume increased, until it capped out at 3x faster on a 450 million row dataset. This result was further corroborated by what we know about Spark. Even with its strengths over Map Reduce computing models, data shuffles are slow and CPU expensive.
We also discovered that if you attempt to cache a table into RAM and there’s overflow, Spark will write the extra blocks to disk, but the read time when coming off of disk is slower than reading the data directly from S3. On top of this, when the cache was completely full, we started to experience memory crashes at runtime because Spark didn’t have enough execution memory to complete the query. When the executors crashed, things slowed to a standstill. Spark scrambled to create another executor, move the necessary data, recreate the result set, etc. Even though uncached queries were slower than the cached ones, this ceases to be true when Spark runs out of RAM.
Takeaway
In terms of power, Spark is unparalleled at performing filtration and aggregation of large datasets. But when it comes to scanning and re-ordering data, Redshift still has Spark beat. This is just our two cents – let us know what you guys think!



